プロジェクトの目的
本プロジェクトでは,特許や論文等の技術文献から自然言語処理技術を用いて様々な知識を抽出・体系化し,これらをジャンル横断検索,技術動向マイニング等に応用する研究に取り組んでいます.
背景
大学における特許検索
大学研究者のこれまでの業績は,著書や論文数によって評価されるのが一般的でしたが,これに加え,近年ではどれだけ特許を出願しているかも,業績のひとつとして重視されるようになってきています.これに伴い,大学の研究者自身が自分の研究と関連のある特許を検索するという機会が増えつつあります.
しかしながら,特許検索の場合,自分の知っている専門用語をいくつか入力して検索しても,目的の特許が得られない場合が少なくありません.なぜならば,一般的に特許は権利の範囲をなるべく広く確保するために,可能な限り一般性の高い用語を使って記述されるためです.また,使用する用語は可能な限り統一する,という慣習が特許では徹底されていないため,ある用語の同義語が大量に存在する,といったことも珍しくありません.
このため,例えば「ワードプロセッサ」に関する特許を検索するには,以下のような検索式が必要になります.
ワードプロセッサ or 文書編集装置 or 文章編集装置 or 文書作成支援装置 or 文章作成支援装置 or 文書作成装置 or 文章作成装置...
さらに,上述のとおり,特許は一般性の高い用語で記述されるため,キーワード検索では関係のない特許が大量に検索結果に含まれてしまう可能性があります.そこで,特許検索の専門家は、キーワードとIPC,FI,Fタームといった特許固有の分類記号を組み合わせて検索します.しかし,このような検索方式は特許に馴染みのない人には敷居が高いため,より簡単で効率的な特許検索方法が必要とされています.
企業における論文検索
企業において,ある製品を作る過程で,どうしても同業他社がすでに特許出願している技術を使わなければ実現できない,といった場合,他社の特許の権利を無効化もしくは範囲を狭めることのできる論文が特許出願以前に発表されていないか調査する場合があります.この場合,特許検索の専門家にとって検索しやすい論文検索システムが必要とされています.
プロジェクトの概要
本プロジェクトでは3つの研究課題に取り組んでいます.
- 技術文献からの知識抽出および体系化
- 特許と論文データベースの統合
- 技術動向の分析
技術文献からの知識抽出および体系化
シソーラスの自動構築および情報検索への応用
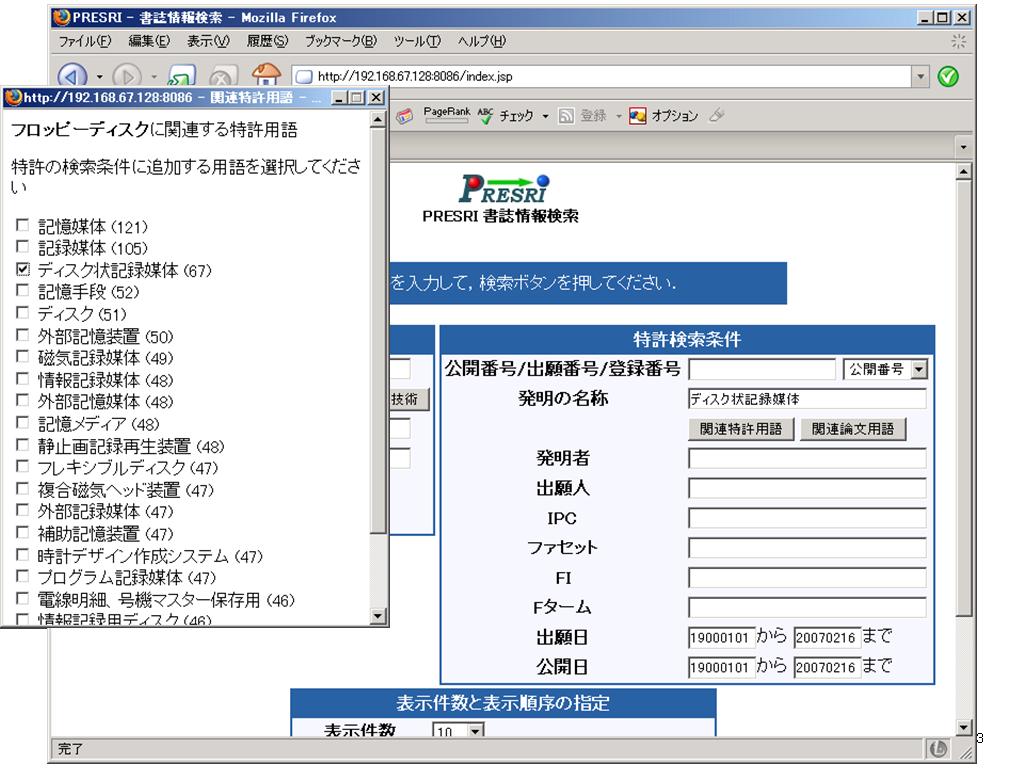
一般に,「A等のB」という表現があった場合,Bの下位語がAであると考えられます.例えば,以下はある公開特許公報中の一文です.
「フロッピーディスクやハードディスク等の磁気ディスクでは、大容量化の要望に応えて高密度記録化が進められている。」
この文から「フロッピーディスク」と「ハードディスク」は「磁気ディスク」の下位語である,という知識が得られます.このような知識を公開特許公報から網羅的に集めることにより,180万語のシソーラスを自動的に構築しています.[難波2007]![]()
この他,「フロッピーディスク(FD)」といった表現から,ある用語とその略語を抽出したり,特許間の引用関係を用いて同義語を自動的に収集する研究も行っています.さらに,これらの知識を用いることで特許の検索精度が向上することも確認しています.[Nanba2007]![]()
入出力に基づいた専門用語の分類
「何を処理するのか」,「システムの入出力は何か」という観点から用語を自動分類する手法を開発しています.専門用語の中には,用語の直後に「する。」を加えることで動詞になるものがあります.例えば,「形態素解析」や「機械翻訳」といった用語に「する。」を加えると「形態素解析する。」や「機械翻訳する。」という表現が得られます.このような表現は,特許や論文中に実際に存在します.こうした用語の多くは,何らかの入力があり,それを処理して新たなものを出力する用語であると考えられます.
ここで,このような文は「AをBにCする。」という文構造になっている場合が少なくありません.この時,ヲ格(A)とニ格(B)を抽出すれば,それがCの入力と出力になっていると考えられます.例えば,Cが「機械翻訳」の場合,ヲ格から「日本語文」や「文書」や「文字列」などが,ニ格から「英語」などが抽出できます.同様に,「形態素解析する。」の場合,ヲ格から「日本語文書」などが抽出できます.そこで,用語ごとに入出力情報を抽出しそれらを比較することで,入出力が似た用語同士をグルーピングすることが可能になります.(特願2007-053771,[近藤2007]![]() )
)
特許と論文データベースの統合
「特許」と「論文」といったジャンルの異なる文書を効率的に検索するためのシステム構築を行っています.具体的には以下の課題に取り組んでいます.
- 特許中の引用文献の自動抽出
- 論文用語の特許用語への自動変換(例えば「DRAM」を「半導体記憶装置」に変換)
特許中の引用文献の自動抽出
特許中の「従来の技術」の項目を解析し,引用特許および引用論文を自動抽出する技術を開発しています.([安善2005]![]() [安善2006]
[安善2006]![]() [小栗2007]
[小栗2007]![]() )
)
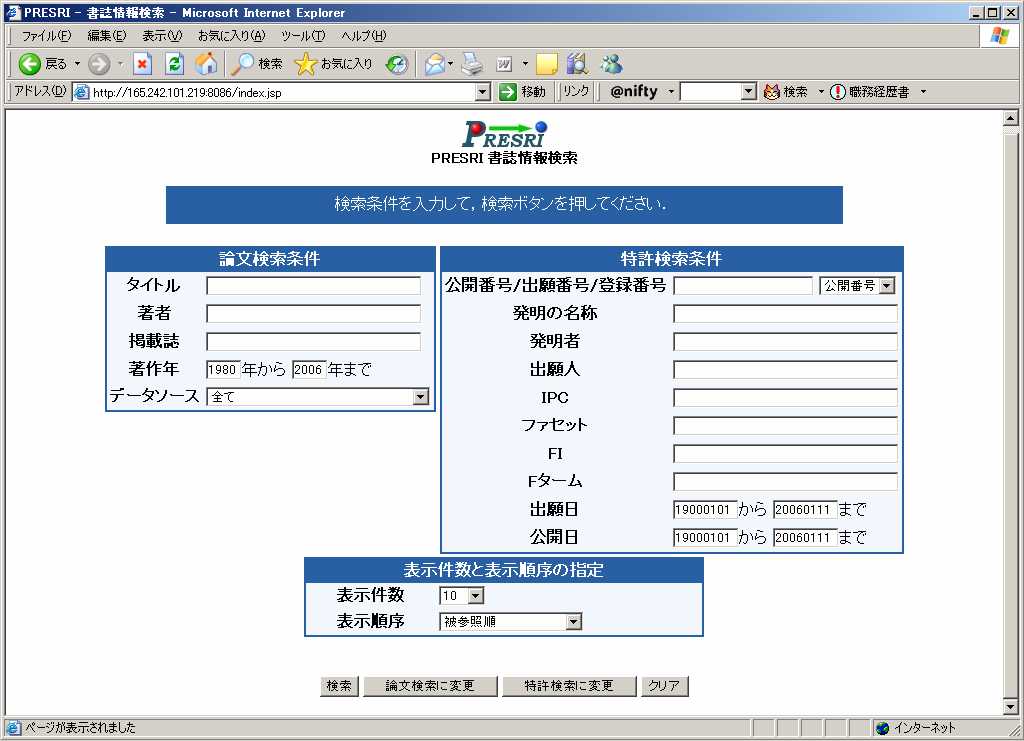 (クリックで画像を拡大)
(クリックで画像を拡大)ユーザは2種類の方法で特許と論文を検索することができます.ひとつはキーワード検索で,もうひとつは特許,論文間の引用関係を用いた検索です.ユーザは,まずキーワード検索を行います.図はキーワード検索の画面です.ユーザは図の検索フォームに,論文の場合はタイトル中の語や著者名などを,特許の場合は発明の名称に含まれる語や発明者や出願人などを入力し,「検索」ボタンを押すと関連する特許や論文が一覧表示されます.なお,この図は特許と論文を同時検索する場合のインタフェースですが,特許のみあるいは論文のみを検索することも可能です.その場合,図の「論文検索に変更」あるいは「特許検索に変更」というボタンを押すことで,検索条件の入力フォームが論文検索用または特許検索用のものに変わります.
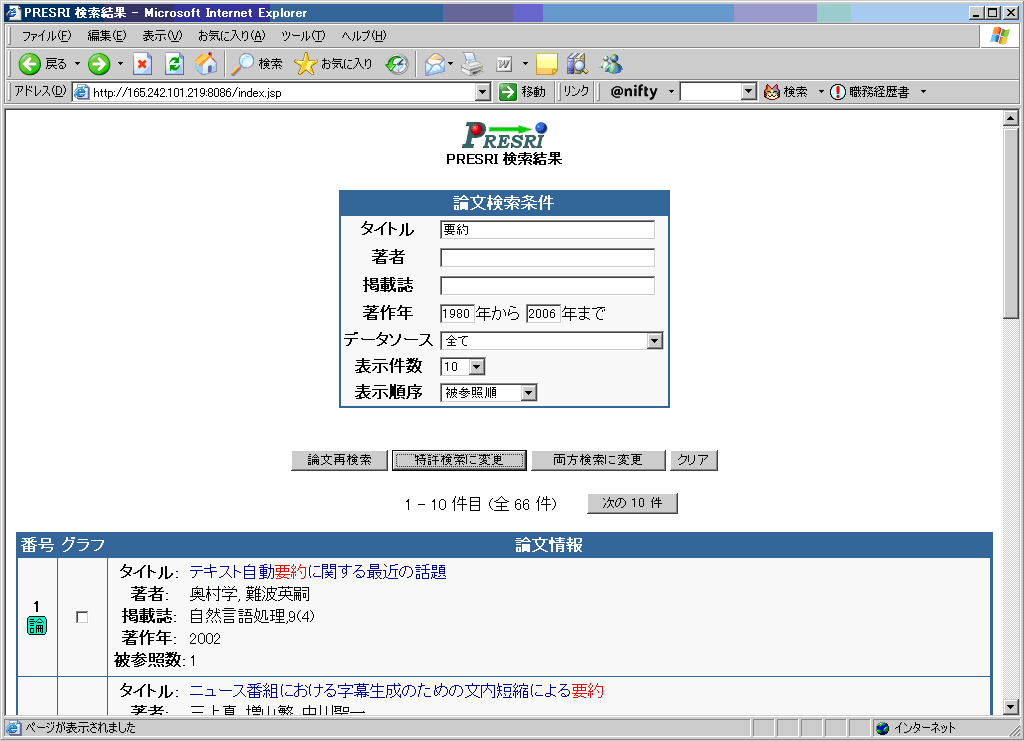 (クリックで画像を拡大)
(クリックで画像を拡大)図は「要約」というキーワードで論文検索を行った場合の例です.検索結果の中でユーザが入力したキーワード(この場合「要約」)は赤字で強調表示されます.検索結果の一覧表示画面では、文献ごとに書誌情報と共にチェックボックスが表示されます.ユーザが興味のある複数の文献にチェックし,「チェックした文献をグラフ表示」というボタンを押すと,チェックした文献およびこれらの文献と引用関係にある特許や論文が,以下の図に示すようなグラフとして表示されます.
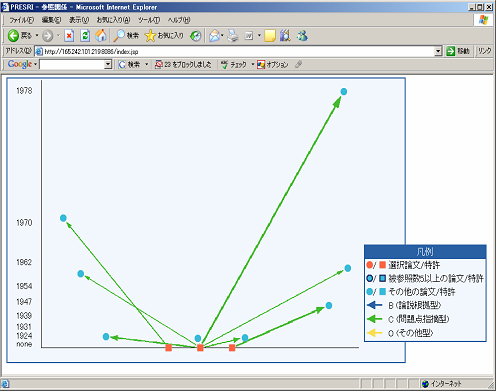 (クリックで画像を拡大)
(クリックで画像を拡大)図において,■は特許を,●は論文を示しています.さらに,「論説根拠型」,「問題点指摘型」,「その他」で表されます.技術文献間の引用関係の種類[6]が矢印の色の違いにより表示されます.なお,グラフ中の■や●の座標は縦軸は著作年であり横軸はランダムな数値を割り当てています.この図では引用関係を示すだけではなく,■や●をクリックすることにより,著者名,表題等の特許や論文の詳細情報を表示することができます.このように,あるトピックに関連する複数の特許や論文をグラフとして提示することで,そのトピックに関する研究や技術動向の直感的・視覚的な理解が可能という利点があります.
論文用語の特許用語への自動変換
この技術は,例えば「DRAM」を「半導体記憶装置」に自動変換することで,より簡単で効率的なジャンル横断検索を実現するというものです.(特開2007-4240,特願2006-065052,[釜屋2006]![]() [釜屋2007]
[釜屋2007]![]() )
)
 (クリックで画像を拡大)
(クリックで画像を拡大)技術動向の分析
テキストマイニング技術を用いて科学技術の進展と動向を視覚的に見ることができるシステムを開発しています.(特願2006-225145,特願2007-053771,[難波2006]![]() [近藤2007]
[近藤2007]![]() )
)
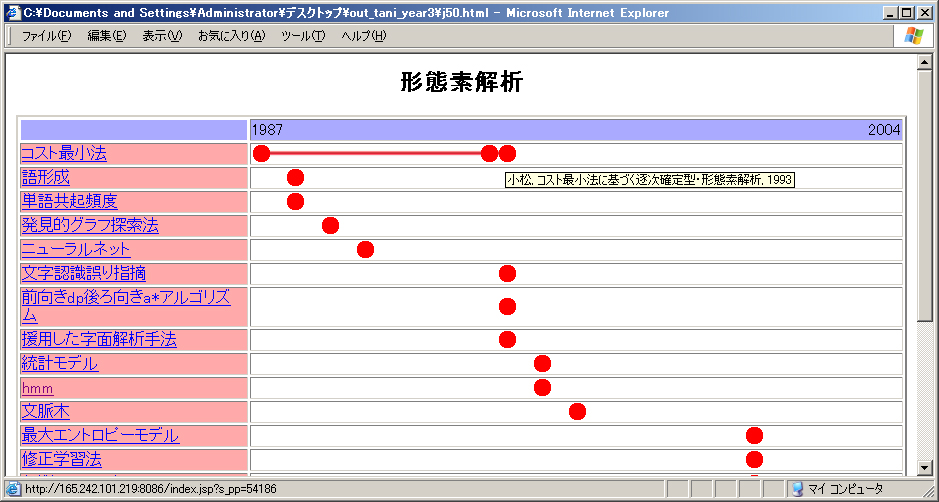 (クリックで画像を拡大)
(クリックで画像を拡大)図は技術動向分析システムの動作例です.「形態素解析」という用語をシステムに入力した時の解析結果を示しています.図において,左端に「形態素解析」の要素技術名が列挙してあり,その用語が論文表題中で使われた年が各技術の右側に示してあります.例えば図3の「コスト最小法」の場合,この用語を論文表題に含んだ形態素解析に関する論文が1987年に1件,1993年に2件発表されています.これらは図中で「●」として表示されており,その間が直線で結ばれています.ユーザが●上にカーソルを重ねると,その論文の書誌情報がポップアップ表示されます.図では「コスト最小法」(一番右端の●)にカーソルを重ねた時のポップアップ表示として「小松, コスト最小法に基づく逐次確定型・形態素解析,1993」が例示されています.
 (クリックで画像を拡大)
(クリックで画像を拡大)図において要素技術として提示されている用語をユーザがクリックすると,その要素技術が他にどのような分野で利用されているのかが一覧表示されます。図は前の図中の“hmm”(隠れマルコフモデル)をクリックした結果を示しています.この図からわかるとおり,1988年には“speech recognition”(音声認識)の分野で,また2001年には“summarization”(要約)の分野でそれぞれ利用されていることがわかります.
関連文献
論文
- 近藤友樹, 難波英嗣, 竹澤寿幸.(2010) “論文と特許からの技術動向マップの自動構築” 言語処理学会 第16回年次大会,114-117.
 (117KB)
(117KB) - 難波英嗣,竹澤寿幸,内山清子,相澤彰子.(2010) “同義語抽出手法を利用した論文用語の特許用語への自動変換” 言語処理学会 第16回年次大会,772-775.(336KB)
- Kondo, T., Nanba, H., Takezawa, T., and Okumura, M. (2009) “Technical Trend Analysis by Analyzing Research Papers' Titles”. In Proceedings of the 4th Language & Technology Conference (LTC'09) , 234-238. (248KB)
- Nanba, H., Kamaya, H., Takezawa, T., Okumura, M., Shinmori, A., and Tanigawa, H. (2009) “Automatic Translation of Scholarly Terms into Patent Terms”. In Proceedings of the 2nd International CIKM Workshop on Patent Information Retrieval (PaIR'09), 21-24. (264KB)
- Nanba, H. and Takezawa, T. (2009) “Classification of Research Papers into a Patent Classification System Using Two Translation Models”. In Proceedings of Workshop on Text and Citation Analysis for Scholarly Digital Libraries,
the Joint Conference of the 47th Annual Meeting of the Association for Computational Linguistics and the 4th International Joint Conference on Natural Language Processing, 27-35. (214KB)
- 難波 英嗣,竹澤 寿幸. (2009) “2種類の翻訳システムを用いた学術論文の特許分類体系への自動分類”『情報処理学会論文誌データベース』,Vol.2,No.3,76-86.(228KB)
- 難波 英嗣,釜屋 英昭,竹澤 寿幸,奥村 学,新森 昭宏,谷川英和. (2009) “論文用語の特許用語への自動変換”『情報処理学会論文誌データベース』,Vol.2,No.1,81-92.(374KB)
- Nanba, H., Anzen, N., and Okumura, M. (2008) “Automatic Extraction of Citation Information in Japanese Patent Applications” International Journal on Digital Libraries, Vol.9, No.2, 151-161. (588KB), [SpringerLink]
- 近藤友樹,難波英嗣,竹澤寿幸.(2008) “翻訳知識を用いた英語論文表題の構造解析” 情報処理学会 自然言語処理研究会, NL-187,37-43.(327KB)
- Nanba, H., Fujii, A., Iwayama, M., and Hashimoto, T. (2008) “Overview of the Patent Mining Task at the NTCIR-7 Workshop”. In Proceedings of the 7th NTCIR Workshop Meeting on Evaluation of Information Access Technologies: Information Retrieval, Question Answering and Cross-lingual Information Access, 325-332. (473KB)
- Nanba, H. (2008) “Hiroshima City University at NTCIR-7 Patent Mining Task”. In Proceedings of the 7th NTCIR Workshop Meeting on Evaluation of Information Access Technologies: Information Retrieval, Question Answering and Cross-lingual Information Access, 369-372. (173KB)
- Taniguchi, Y. and Nanba, H. (2008) “Identification of Bibliographic Information Written in both Japanese and English”. 12th European Conference on Research and Advanced Technology for Digital Libraries, ECDL 2008, Aarhus, Denmark. Poster Session (74KB)
- 釜屋英昭,難波英嗣,竹澤寿幸,奥村学.(2008) “論文用語の特許用語への自動変換” 言語処理学会 第14回年次大会,801-804.(124KB)
- 難波英嗣,奥村学,新森昭宏,谷川英和.(2007) “特許と論文を対象にした技術動向分析” Japio Year Book.
- 難波英嗣.(2007)“知財活用の実際 論文と特許データベースを統合したジャンル横断検索および技術動向分析”『情報の科学と技術』,57巻10号,483-487.
- Nanba, H. (2007) “Query Expansion using an Automatically Constructed Thesaurus ”. In Proceedings of the 6th NTCIR Workshop, 414-419. (222KB)
- 釜屋英昭,難波英嗣,奥村学,新森昭宏,谷川英和,鈴木泰山.(2007) “特許,論文間の引用情報を用いた論文用語の特許用語への変換” 情報処理学会 自然言語処理研究会, NL-178,97-102.(259KB)
- 難波英嗣,奥村学,新森昭宏,谷川英和,鈴木泰山.(2007) “特許データベースからのシソーラスの自動構築” 言語処理学会 第13回年次大会,1113-1116.(193KB)
- 近藤友樹,難波英嗣,奥村学,新森昭宏,谷川英和,鈴木泰山.(2007) “論文データベースからの研究動向情報の抽出” 言語処理学会 第13回年次大会,470-473.(417KB)
- 小栗佑実子,難波英嗣.(2007) “米国特許データベースからの引用文献情報の抽出” 言語処理学会 第13回年次大会,582-585.(153KB)
- 難波英嗣,釜屋英昭,奥村学,谷川英和,新森昭宏,鈴木泰山,宮原俊一.(2006) “特許,論文データベースを統合した検索環境および動向分析ツールの構築” 第3回情報プロフェッショナルシンポジウム(INFOPRO 2006),(76KB)
- 難波英嗣,谷口裕子.(2006) “学術論文データベースからの研究動向情報の抽出と可視化” 言語処理学会 第12回年次大会 併設ワークショップ「言語処理と情報可視化の接点」(132KB)
- 安善奈津美,難波英嗣,相沢輝昭,奥村学.(2006) “特許,論文データベースを統合した検索環境の構築” 言語処理学会 第12回年次大会, pp.743-746, (122KB)
- 釜屋英昭,難波英嗣,相沢輝昭,新森昭宏,奥村学.(2006) “特許,論文間の引用関係を用いた論文用語の特許用語への変換” 言語処理学会 第12回年次大会, pp.779-782 (80KB)
- 安善奈津美,難波英嗣,相沢輝昭,奥村学.(2005) “特許、論文データベースを統合した検索環境の構築” 情報処理学会 自然言語処理研究会, NL-168,pp.21-26,(101KB)
- 難波英嗣. (2005) “論文間の引用情報を利用した関連用語の自動収集” 言語処理学会 第11回年次大会 (58KB)
特許
国内出願
- 特開2007-4240「情報処理装置,情報処理システム,およびプログラム」,発明者:難波英嗣,出願人:難波英嗣(2005/6/21)(ひろしま産業振興機構に譲渡済み)
- 特願2006-065052「関連用語取得装置,関連用語取得方法,及びプログラム」,発明者:難波英嗣,出願人:難波英嗣(2006/3/5)(ひろしま産業振興機構に譲渡済み)
- 特願2006-225145「技術動向情報作成装置、技術動向情報作成方法、及びプログラム」,発明者:難波英嗣,出願人:難波英嗣(2006/8/22)(ひろしま産業振興機構に譲渡済み)
- 特願2007-053771「専門用語分類装置,専門用語分類方法,及びプログラム」,発明者:難波英嗣,出願人:難波英嗣(2007/3/5)
- 特願2007-112532「情報処理装置,情報処理方法,及びプログラム」,発明者:難波英嗣,出願人:難波英嗣(2007/4/23)
国際出願
- US Patent Application No.: 11/368,610(基礎出願番号:特願2005-180435)“Information Processing Apparatus, Information Processing System, and Program”, Inventor & Applicant: Hidetsugu Nanba(2006/3/7)
- PCT国際出願(基礎出願番号:特願2006-065052,特願20060225145)「関連用語取得装置,関連用語取得方法,技術動向情報作成装置,技術動向情報作成方法,及びプログラム」,発明者:難波英嗣,出願人:難波英嗣(2007/3/6)
その他
- 難波英嗣,奥村学,高村大也.(2006) “特許、論文データベースを統合した検索環境および動向分析ツールの構築” イノベーション・ジャパン2006,主催:科学技術振興機構,新エネルギー・産業技術総合開発機構
研究助成
- 科学研究費補助金(若手研究(B))(2010-2012) (3,000,000円)
- 難波英嗣「同義語抽出手法を利用した論文用語の特許用語への自動変換および情報検索への応用」
- 受託研究費(日本マイクロシステムズ株式会社)(2008) (1,000,000円)
- 難波英嗣,竹澤寿幸「テキストマイニング要素技術の研究・開発」
- 科学研究費補助金(若手研究(B))(2007-2009) (3,200,000円)
- 難波英嗣「連接語に着目した専門用語の体系化および技術動向分析への応用」
- 新エネルギー・産業技術総合開発機構(NEDO) 産業技術研究助成事業 (2004-2006) (27,300,000円)
- 難波英嗣, 奥村学, 高村大也「特許、論文データベースを統合した検索環境および動向分析ツールの構築」